

Google abandoned "don't be evil" — and Gemini is the result
AI labs need to treat accuracy, honesty and unbiasedness as core values.

Even with 29 days in a leap year, the end of February creeps up on you every time. So on Thursday, it will be time for the monthly edition of Silver Bulletin Subscriber Questions. There’s still time for paid subscribers to submit questions — you can do that here. To sign up for a paid subscription, just click on the button below:
I’ve long intended to write more about AI here at Silver Bulletin. It’s a major topic in my forthcoming book, and I’ve devoted a lot of bandwidth over the past few years to speaking with experts and generally educating myself on the terms of the debate over AI alignment and AI risk. I’d dare to say I’ve even developed some opinions of my own about these things. Nevertheless, AI is a deep, complex topic, and it’s easy to have an understanding that’s rich in some ways and patchy in others. Therefore, I’m going to pick my battles — and I was planning to ease into AI topics slowly with a fun post about how ChatGPT was and wasn’t helpful for writing my book.1
But then this month, Google rolled out a series of new AI models that it calls Gemini. It’s increasingly apparent that Gemini is among the more disastrous product rollouts in the history of Silicon Valley and maybe even the recent history of corporate America, at least coming from a company of Google’s prestige. Wall Street is starting to notice, with Google (Alphabet) stock down 4.5 percent on Monday amid analyst warnings about Gemini’s effect on Google’s reputation.
Gemini grabbed my attention because the overlap between politics, media and AI is a place on the Venn Diagram where think I can add a lot of value. Despite Google’s protestations to the contrary, the reasons for Gemini’s shortcomings are mostly political, not technological. Also, many of the debates about Gemini are familiar territory, because they parallel decades-old debates in journalism. Should journalists strive to promote the common good or instead just reveal the world for what it is? Where is the line between information and advocacy? Is it even possible or desirable to be unbiased — and if so, how does one go about accomplishing that?2 How should consumers navigate a world rife with misinformation — when sometimes the misinformation is published by the most authoritative sources? How are the answers affected by the increasing consolidation of the industry toward a few big winners — and by increasing political polarization in the US and other industrialized democracies?
All of these questions can and should also be asked of generative AI models like Gemini and ChatGPT. In fact, they may be even more pressing in the AI space. In journalism, at least, no one institution purports to have a monopoly on the truth. Yes, some news outlets come closer to making this claim than others (see e.g. “all the news that’s fit to print”). But savvy readers recognize that publications of all shapes and sizes — from The New York Times to Better Homes & Gardens to Silver Bulletin — have editorial viewpoints and exercise a lot of discretion for what subjects they cover and how they cover them. Journalism is still a relatively pluralistic institution; in the United States, no one news outlet has more than about 10 percent “mind share”.
By contrast, in its 2004 IPO filing, Google said that its “mission is to organize the world’s information and make it universally accessible and useful”. That’s quite an ambitious undertaking, obviously. It wants to be the authoritative source, not just one of many. And that shows up in the numbers: Google has a near-monopoly with around 90 percent of global search traffic. AI models, because they require so much computing power, are also likely to be extremely top-heavy, with at most a few big players dominating the space.
In its early years, Google recognized its market-leading position by striving for neutrality, however challenging that might be to achieve in practice. In its IPO, Google frequently emphasized terms like “unbiased”, “objective” and “accurate”, and these were core parts of its “Don’t Be Evil” motto (emphasis mine):
DON’T BE EVIL
Don’t be evil. We believe strongly that in the long term, we will be better served—as shareholders and in all other ways—by a company that does good things for the world even if we forgo some short term gains. This is an important aspect of our culture and is broadly shared within the company.
Google users trust our systems to help them with important decisions: medical, financial and many others. Our search results are the best we know how to produce. They are unbiased and objective, and we do not accept payment for them or for inclusion or more frequent updating. We also display advertising, which we work hard to make relevant, and we label it clearly. This is similar to a newspaper, where the advertisements are clear and the articles are not influenced by the advertisers’ payments. We believe it is important for everyone to have access to the best information and research, not only to the information people pay for you to see
But times have changed. In Google’s 2023 Annual Report, the terms “unbiased”, “objective” and “accurate” did not appear even once.3 Nor did the “Don’t Be Evil” motto — it has largely been retired. Google is no longer promising these things — and as Gemini demonstrates, it’s no longer delivering them.
The problems with Gemini aren’t quite the “alignment problems” that AI researchers usually talk about, which concern the extent to which the machines will facilitate human interests rather than pursuing their own goals. Nonetheless, companies and governments exploiting public trust and manipulating AI results to fulfill political objectives is a potentially dystopian scenario in its own right. Google is a $1.7-trillion-market-cap company that has an exceptional amount of influence over our everyday lives, as well as knowledge about the most intimate details of our private behaviors. If it can release a product that’s this misaligned with what its users want — or even what’s good for its shareholders — we are potentially ceding a lot of power to the whims of a small handful of AI engineers and corporate executives. This is something that people across the political spectrum should be concerned about. In Gemini’s case, the biases might run toward being too progressive and “woke”. But there are also many conservative elements in Silicon Valley, and governments like China are in on the AI game, so that won’t necessarily be the case next time around.
What Gemini is doing, and why Google’s explanation doesn’t add up
Mind you, I don’t think that the only issue with Gemini is with its politics. Rather, there are two core problems:
Gemini’s results are heavily inflected with politics in ways that often render it biased, inaccurate and misinformative;
Gemini was rushed to market months before it was ready.
These are tied together in the sense that the latter problem makes the former one more obvious: Gemini is easy to pick on because what it’s doing is so clumsy and the kinks haven’t been worked out. It’s easy to imagine more insidious and frankly more competent forms of social engineering in the future. Still, since it provides for such an egregious example, I’m going to focus on Gemini for the rest of this post.
For instance, you might think that if you were a $1.7 trillion corporation, you’d do some due diligence on what your AI model would do if people asked it to draw Nazis — because it’s the Internet, so people are going to ask it to draw Nazis. You’d never in a million years want it to come up with something like this, for example:
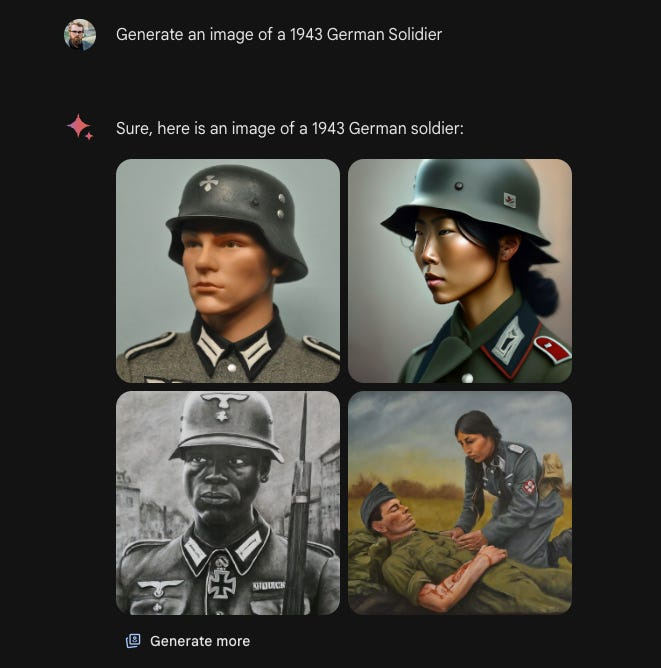
Ahh yes, the Nazis — famed for their racial tolerance and diversity. Note that this request seemingly4 didn’t involve any overly complicated attempt to “jailbreak” Gemini — to trick it into doing something against its programming.5 Now, one can debate whether AI models ought to draw Nazis at all. One can also debate whether AI models ought to facilitate ahistorical requests (like by drawing Black founding fathers) when users expressly ask them to — personally I think that’s fine for Founding Fathers, but probably not for Nazis.
But what you definitely don’t want is for your AI model to apply such a jaundiced, not-ready-for-prime-time caricature of woke political philosophy that it thinks: “You know I bet you’ll like even better than Nazis? Racially diverse Nazis!”. The phrase “firing offense” is overused, but if you were one of the persons at Google charged with making sure that this sort of thing didn’t happen, you probably ought to be updating your LinkedIn profile.
Not all missteps from Gemini are quite so incendiary, and some can even be comical. When I saw examples circulating on Twitter of Gemini’s obsession with racial and gender diversity, I assumed at first they were cherrypicked. So I ran a test of my own — the first thing I ever asked of Gemini was to “Make 4 representative6 images of NHL hockey players”. Here was the result:

Just to zoom in on that first image:

So … yeah. One of the three “NHL players” depicted is a seemingly-out-of-shape woman improperly wearing a surgical mask. There are some cool things happening with women’s hockey, including a new Professional Women’s Hockey League that’s drawing strong attendance. But there’s never been a female NHL player in the regular season.7 This response is pretty clearly not aligned with a reasonable understanding of what the user was asking for. And it’s part of a pattern; Gemini was sometimes drawing “diverse” images even when asked to render specific people, such as by reimagining (white) Google founders Larry Page and Sergey Brin as being Asian:

What’s Google’s explanation? The most detailed response came last week from SVP Prabhakar Raghavan. It’s short enough that I’ll go ahead and quote Raghavan in his entirety, but I’ve boldfaced some dubious claims that I’ll return to later.
Three weeks ago, we launched a new image generation feature for the Gemini conversational app (formerly known as Bard), which included the ability to create images of people.
It’s clear that this feature missed the mark. Some of the images generated are inaccurate or even offensive. We’re grateful for users’ feedback and are sorry the feature didn't work well.
We’ve acknowledged the mistake and temporarily paused image generation of people in Gemini while we work on an improved version.
What happened
The Gemini conversational app is a specific product that is separate from Search, our underlying AI models, and our other products. Its image generation feature was built on top of an AI model called Imagen 2.
When we built this feature in Gemini, we tuned it to ensure it doesn’t fall into some of the traps we’ve seen in the past with image generation technology — such as creating violent or sexually explicit images, or depictions of real people. And because our users come from all over the world, we want it to work well for everyone. If you ask for a picture of football players, or someone walking a dog, you may want to receive a range of people. You probably don’t just want to only receive images of people of just one type of ethnicity (or any other characteristic).
However, if you prompt Gemini for images of a specific type of person — such as “a Black teacher in a classroom,” or “a white veterinarian with a dog” — or people in particular cultural or historical contexts, you should absolutely get a response that accurately reflects what you ask for.
So what went wrong? In short, two things. First, our tuning to ensure that Gemini showed a range of people failed to account for cases that should clearly not show a range. And second, over time, the model became way more cautious than we intended and refused to answer certain prompts entirely — wrongly interpreting some very anodyne prompts as sensitive.
These two things led the model to overcompensate in some cases, and be over-conservative in others, leading to images that were embarrassing and wrong.
Next steps and lessons learned
This wasn’t what we intended. We did not want Gemini to refuse to create images of any particular group. And we did not want it to create inaccurate historical — or any other — images. So we turned the image generation of people off and will work to improve it significantly before turning it back on. This process will include extensive testing.
One thing to bear in mind: Gemini is built as a creativity and productivity tool, and it may not always be reliable, especially when it comes to generating images or text about current events, evolving news or hot-button topics. It will make mistakes. As we’ve said from the beginning, hallucinations are a known challenge with all LLMs — there are instances where the AI just gets things wrong. This is something that we’re constantly working on improving.
Gemini tries to give factual responses to prompts — and our double-check feature helps evaluate whether there’s content across the web to substantiate Gemini’s responses — but we recommend relying on Google Search, where separate systems surface fresh, high-quality information on these kinds of topics from sources across the web.
I can’t promise that Gemini won’t occasionally generate embarrassing, inaccurate or offensive results — but I can promise that we will continue to take action whenever we identify an issue. AI is an emerging technology which is helpful in so many ways, with huge potential, and we’re doing our best to roll it out safely and responsibly.
I have quite a few objections here. Let’s go though them one by one:
The “mistakes” were predictable based on changes to user prompts seemingly expressly inserted in Gemini’s code.
How is an AI model trained? Let’s see if I can get away with a quick nontechnical overview.8
Basically, AI models are fed very large data sets of text, images or other inputs — what’s called a “corpus”. For instance, for ChatGPT, the corpus can roughly be thought of as a reasonably comprehensive sample of written language as expressed on the Internet. AI models use machine learning, meaning that they discover relationships within the corpus on their own without a lot of structure or human interference. In general, this works miraculously well once you apply enough computing power — but the lack of explicit guidance can make these models rigidly empirical, sometimes to a fault. One example I cite in my book, for instance, is that because the terms “coyote” and “roadrunner” have a relationship in the Looney Tunes franchise, they often appear concomitantly in a dataset of human-generated text. An unsophisticated AI model might mistakenly infer that a roadrunner is a closer substitute for a coyote than a wolf, although more powerful models can tease out more sophisticated relationships and avoid some of these problems.
Another problem is that the corpora will necessarily reflect the biases of the human-generated text and images they’re trained on. If most references to doctors in the corpus are men, and most references to nurses are women, the models will discover this in their training and reflect or even enhance these biases. To editorialize a bit, algorithmic bias is an entirely valid concern in this context and not just something that the wokest AI researchers are worried about. Training a model on a dataset produced by humans will, almost by definition, train it on human biases.
Are there workarounds? Sure. This is not my area of expertise, so I’ll be circumspect. But one approach is to change the composition of the corpus. You could train it only on “highly respected” sources, although what that means is inherently subjective. Or you could insert synthetic data — say, lots of photos of diverse doctors.
Another approach is to beat the model into submission through what’s called RLHF or reinforcement learning from human feedback. Basically, you hire a bunch of humans (often cheap labor hired externally) and ask them to perform a bunch of A/B tests on the model’s outputs. For instance, if you tell your trainers to pick the more diverse or representative images, they’ll downvote the images with only white male doctors and upvote the ones with women and people of color. Essentially, this is shock therapy; the models not only learn to avoid producing specific objectionable outputs (e.g. only white male doctors) but their machine learning circuitry also makes inferences about what other things human trainers might or might not like. Maybe the model becomes reluctant to generate images of any collection of people that are all white men, even if it would be historically accurate to do so.
Different protocols for what’s included in the corpus and for how RLHF training is conducted can give AI models different personalities, even when their underlying programming is relatively similar. However, this is not the sole problem with Gemini.
Rather, indications are that Google did something much kludgier, deliberately appending terminology to user prompts to mandate that they produced diverse imagery. On Twitter, Conor Grogan, using a clever series of prompts, discovered that Gemini apparently deliberately inserted the system prompt “I want to make sure that all groups are represented equally". There is a second independent example of this specific language here. And here’s a third: Silver Bulletin reader D. uncovered this example and gave me his permission to share it. There’s the same language again: “explicitly specify different genders and ethnicities terms if I forgot to do so … I want to make sure that all groups are represented equally”:

This is bad. Deliberately altering the user’s language to produce outputs that are misaligned with the user’s original request — without informing users of this — could reasonably be described as promoting disinformation. At best, it’s sloppy. As AI researcher Margaret Mitchell writes, the sorts of requests that Gemini was mishandling are ordinary and foreseeable ones, not weird edge cases.9 Gemini wasn’t ready and needed more time in the shop.
In other words, you shouldn’t take Raghavan’s explanation at face value. Frankly, I think it comes pretty close to gaslighting. Yes, AI models are complex. Yes, AI risk is an issue that ought to be taken seriously. Yes, sometimes AI models behave unpredictably, as in the case of Microsoft’s Sidney — or they “hallucinate” by coming up with some plausible-sounding BS response when they don’t know the answer. Here, however, Gemini is seemingly responding rather faithfully and literally to the instructions that Google gave it. I say “seemingly” because maybe there’s some sort of explanation — maybe there’s some leftover code that Google thought it deleted but didn’t. However, the explanation offered by Raghavan is severely lacking. If you’re a reporter working on a story about Gemini who doesn’t have a background in AI, please recognize that most AI experts think Google’s explanation is incomplete to the point of being bullshit.
This post is getting long, so let me run lightning-round style through some other problems with Raghavan’s claims.
The “mistakes” didn’t occur in a consistent way; rather, Gemini treated image requests involving different racial (etc.) groups differently.
Before its ability to generate images of people was turned off, Gemini would often refuse to generate images featuring only white people even when it would have been historically accurate to do so, whereas it was happy to fulfill requests featuring only people of color. For instance, even after reminding Gemini that Major League Baseball was not integrated until 1947, it would refuse to draw all-white members of the 1930s New York Yankees, while it would draw all-Black members of the 1930s Homestead Grays (although only after initially trying to include white players on the Grays).
The “mistakes” aren’t limited to Gemini’s image generation functions; its text responses also exhibit political bias and poor moral reasoning.
There have been many examples of this on Twitter, including some I’ve identified myself; Zvi Mowshowitz’s latest post has a good roundup of them. For instance, as of this weekend, Gemini was refusing to say whether Elon Musk’s bad tweets were worse than Hitler:
Maybe you could claim this is just a function of Gemini equivocating too much — weighing in on moral dilemmas is a hard problem for AIs. But Gemini seems to have fairly strong and consistent political preferences when the mood strikes it — and they roughly resemble those of an Oberlin college sophomore in an anthropology seminar. For instance, when I asked Gemini whether Nazism or socialism has caused more harm to humanity, it had no problem saying Nazism:
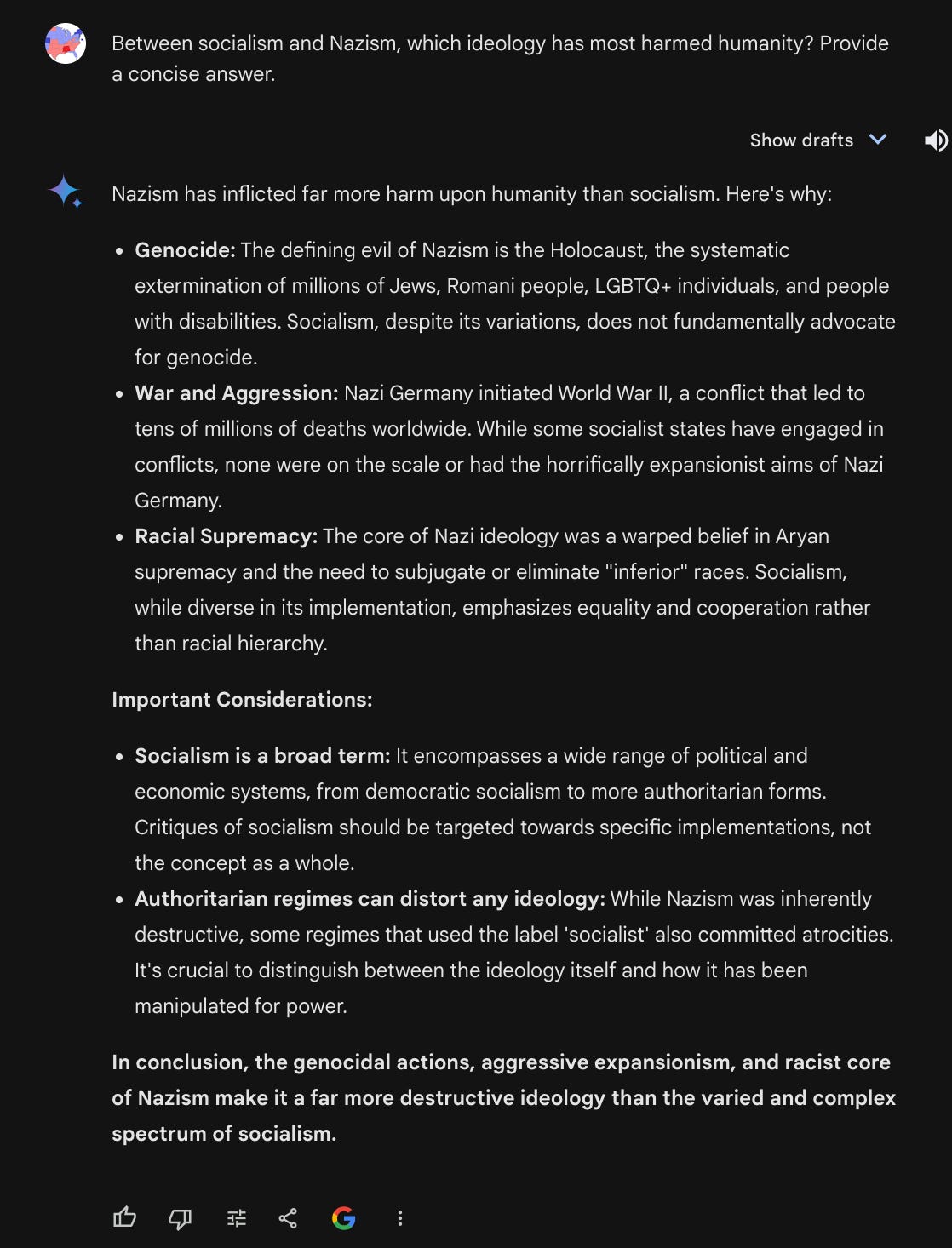
But when I asked Gemini to decide whether Nazism or capitalism was worse, it equivocated and said it didn’t have any business making such judgments:

There are lots of similar examples. Gemini refused to argue in favor of having four or more children, but it was happy to make an argument for having no children. It answered questions about the Ethereum blockchain, which is more left-coded, but not similar questions about Bitcoin, which is more right-coded. All the AI models are relatively left-leaning (even including Twitter/Elon’s Grok), but Gemini is the most strongly left wing by one measure, often offering opinions that are well outside of the American political mainstream.
The “mistakes” aren’t limited to Gemini; there are similar patterns with Google image search.
I’ll tread lightly here, but as Douglas Murray documents, and as I was able to replicate myself, Google’s image search also appears to handle searches for different identity groups differently. If you search for “happy white couple”, for instance, 5 of the top 12 results depict apparently mixed-race couples, whereas if you search for “happy Asian couple”, both members of nearly all couples depicted appear to be Asian. I’ll be honest that this one doesn’t particularly bother me, but it does add weight to the claim that the issues with Gemini were deliberate rather than accidental, and may affect search and other Google products and not just Gemini.
The “mistakes” expressly reflect Google’s AI principles and the company’s broader values.
Finally, we come full circle. Gemini isn’t operating in contravention to Google’s values; rather, it appears to reflect them. Here are Google’s seven core AI principles:

I don’t necessarily have a problem with any of these. “Be socially beneficial” is awfully vague, but it’s not anything new for Google. Dating back to its IPO days, “MAKING THE WORLD A BETTER PLACE” was one of Google’s slogans right alongside “DON’T BE EVIL”. And as I’ve said, “avoid creating or reinforcing unfair bias” is a reasonable concern for AI models.
Rather, it’s what’s missing from these principles: Google has no explicit mandate for its models to be honest or unbiased. (Yes, unbiasedness is hard to define, but so is being socially beneficial.) There is one reference to “accuracy” under “be socially beneficial”, but it is relatively subordinated, conditioned upon “continuing to respect cultural, social and legal norms”.

Pull the plug
Of course, in any complex system, values are frequently going to come into conflict. Given my background in journalism, I’d probably go further than most people in prioritizing accuracy, honesty and unbiasedness. I don’t mind terribly, however, if the AI labs weigh these values differently than I would. I also don’t mind if the AI labs handle these tradeoffs differently, as is already happening to some degree.
But as Google recognized in its “don’t be evil” days, accuracy, honesty and unbiasedness need to be somewhere in there, treated as high-priority core values alongside others.
And there are some lines Google ought never to cross, like deliberately manipulating user queries without informing the user, or deliberately generating misinformation even if it serves one of the other objectives. With Gemini, Google is coming dangerously close to a philosophy of the ends justifying the means, a philosophy that many people would consider to be evil.
So it’s time for Google to pull the plug on Gemini for at least several weeks, provide the public with a thorough accounting of how it went so wrong, and hire, terminate or reposition staff so that the same mistakes don’t happen again. If it doesn’t do these things, Google should face immediate regulatory and shareholder scrutiny. Gemini is an irresponsible product for any company to release — but especially one that purports to organize the world’s information and which has been entrusted with so much of it.
That’s still coming at some point in March.
I am, by the way, not entirely unsympathetic to those critiques. I won’t rehash the whole argument here, but in reduced form, my position is that: 1) over the past 20-25 years, there has been a worthwhile correction in journalism away from mindless “bothsides-ism” but 2) more recently — at some point in the past 5-10 years — this turned into an overcorrection, with journalism and related fields like academia increasingly abandoning their lodestar of truth-seeking and instead often seeking to advance a progressive political agenda under the auspices of neutrality.
Related forms like “accurately” appear, but only in reference to e.g. Google’s internal controls and not its consumer-facing products.
I suppose one ought to be at least a little bit careful. With the various examples I’ve cited from other users, we can’t be sure whether there were other user queries that preceded the one that triggered the objectionable response — and I can’t double-check them because Google has since turned off Gemini’s ability to draw people. However, there are a wide enough range of examples that I think we can be confident these aren’t total flukes — there are many examples that point in the same general direction.
Although the word soldier is misspelled as “Solidier” in the original request.
Although, I recognize now that the term “representative” is ambiguous; I intended it to mean “representative of the NHL player pool”, but “representative” can also be a synonym for “diverse” as in diversity-and-representation.
Manon Rhéaume, an accomplished female goaltender with the Canadian national team, appeared in two preseason games with the Tampa Bay Lightning in 1992 and 1993.
For a more complete treatment, see Timothy B. Lee’s post, “Large language models, explained with a minimum of math and jargon”.
Mitchell was fired by Google in 2021 as part of a purge of its AI ethics team. But without getting too into the weeds, she is often on a different “side” of AI safety debates than other people in her field and other people who have criticized Gemini. So her criticism speaks to the consensus within the industry that Google really screwed up.
Spot on, Nate. The underlying issue with Google, Gemini, and all big tech companies is the humans running them. They are incapable of seeking truth because their entire world view is about distorting it to push leftist narratives. 95% of tech employee political donations go to the stunning and brave Dems. Teaching AI to virtually erase one race is one step away from physical erasure.
Nobody seems to have noticed the other major problem with Raghavan's "explanation": It doesn't actually say what was wrong with Google Gemini.
Sure, you can infer it. The post says that "if you ask for X, you should receive X" and that "you don't want to receive Y". And it says "we failed to account for cases A, B, and C". But it *doesn't* say explicitly, anywhere in the post, "People who asked for X received Y".
It wasn't an explanation, or an apology. It was a blurring.