

Why I don't buy 538's new election model
It barely pays attention to the polls. And its results just don't make a lot of sense.

This was originally going to be a Model Talk column, our weekly feature for paying subscribers. But, since I’ve received numerous requests for public comment about this, I think I need to put it in front of the paywall. We’ll make it up to paid subscribers with another post later this week or this weekend.
When the Silver Bulletin presidential forecast launched last month, I said I wasn’t interested in prosecuting the “model wars”, meaning having big public debates about forecasting methodology. One reason is that I find these arguments tiresome: I first published an election model in 2008, and it’s been the same debates pretty much ever since. But there’s also a more pragmatic consideration. If I think a model is unsound, I worry about elevating it by giving it even more attention. Because I do believe in probabilities, after all. Joe Biden’s chance of winning another term is hard to forecast because (1) he might still drop out and (2) he’s probably not capable of running the sort of normal campaign the model implicitly assumes he can. Biden’s chances are probably lower than the current 28 percent in the Silver Bulletin forecast, in other words. But they’re certainly not zero. I worry about a news cycle on Nov. 6 when an unsound model is validated because it “won” the model wars based on a sample size of one election.
What also makes this awkward is that the model I’m going to criticize comes from the site I used to work for, 538. I’m sure newsletter readers will know this, but what was formerly the FiveThirtyEight model1 from 2008-2022 is now the Silver Bulletin model — I retained the IP when I left Disney. But, I’m not sure the rest of the world knows that. (I still sometimes run into people who think FiveThirtyEight is affiliated with the New York Times, which it hasn’t been since 2013.) I worry a little bit about a Naomi Klein / Naomi Wolf situation in which criticism of the 538 model rebounds back on me.
Let’s also state the other and more obvious conflicts here: I publish a competing product. And I’m not a fan of the guy 538 hired to develop its new model, G. Elliott Morris.
However, various high-profile reporters have contacted me for comment. And I think I have a professional obligation to speak up. Not all that many people have explored the inner workings of models like these. Moreover, we’re in an unusual circumstance where the models themselves have become part of the debate about what Biden should do. For instance, the 538 model — which showed Biden with a 53 percent chance of winning as of Thursday afternoon — has been cited by Biden defenders like Ron Klain, the former White House Chief of Staff, as a reason that Biden should stay in the race:
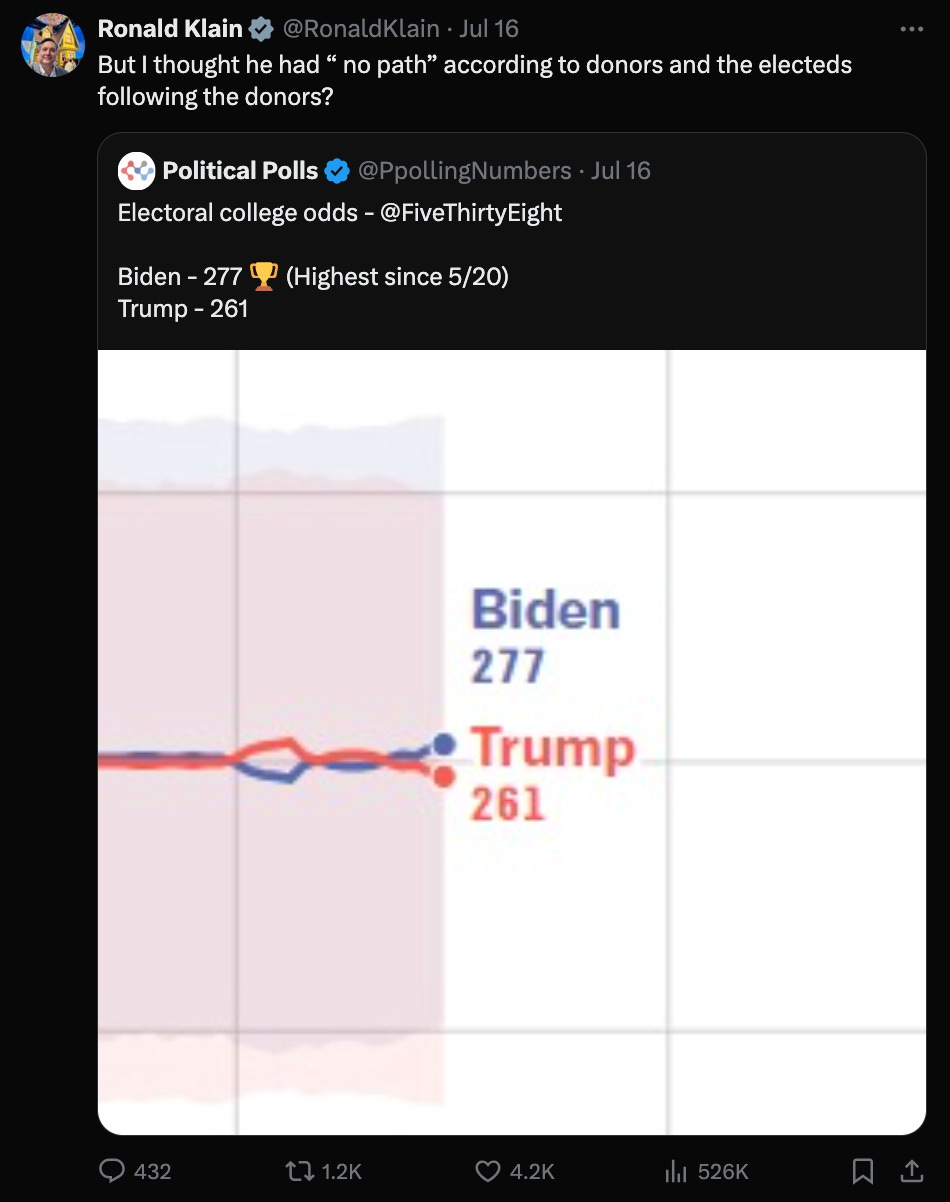
I’m not sure that Klain or anyone else should get their hopes up from the 538 model, however. At best, all it’s really saying is that Biden will probably win because he’s an incumbent: the polls have very little influence on the 538 forecast at this point. And at worst, it might be buggy. It’s not easy to understand what it’s doing or why it’s doing it.
Feature or bug?
I thought the 538 model seemed basically reasonable when it was first published in June, showing the race as a toss-up. But its behavior since the debate — Biden has actually gained ground in their forecast over the past few weeks even though their polling average has moved toward Trump by 2 points! — raises a lot of questions. This may be by design — Morris seems to believe it’s too early to really look at the polls at all. But If my model was behaving like this, I’d be concerned.
Moreover, some of the internal workings of the model are strange, or at least appear that way based on the information Morris has made publicly available.
In the Silver Bulletin model, we take steps that are roughly similar to the 538 model. First, we take a current “snapshot” of the race — which is based on polling, although with some fancy adjustments to smooth out the data in states where there isn’t much polling — and then regress it toward a prior based on “fundamentals” (which in our case consist of the economy and incumbency).
Right now, for instance, Biden trails by about 2 points nationally in our polling-based estimate, but our fundamentals forecast says he “should” eventually win the popular vote by roughly 2.5 points. Currently, our model uses roughly a 70/30 blend of the snapshot and the fundamentals.
(-2.0 x 70%) + (2.5 x 30%) = -0.6Blending the polls and fundamentals yields a mix where Biden is projected to lose the popular vote by around 0.6 points — not so bad, actually, but keep in mind that Biden’s Electoral College position is considerably worse than his standing in the popular vote.
Still, though, I hope the logic is reasonably easy to follow. Our final forecast reflects a blend between polls and fundamentals. By contrast, look at 538’s forecast in Wisconsin:

538 projects Trump to lead the polling average by 2.7 points in Wisconsin on Election Day. And it thinks the fundamentals basically show a tie (Biden ahead, but by only 0.2 points). And yet somehow, it predicts Biden to win by 1.3 points in their “full forecast”. This doesn’t make a lot of sense.
Now, to be fair, this isn’t happening with 538’s national numbers:
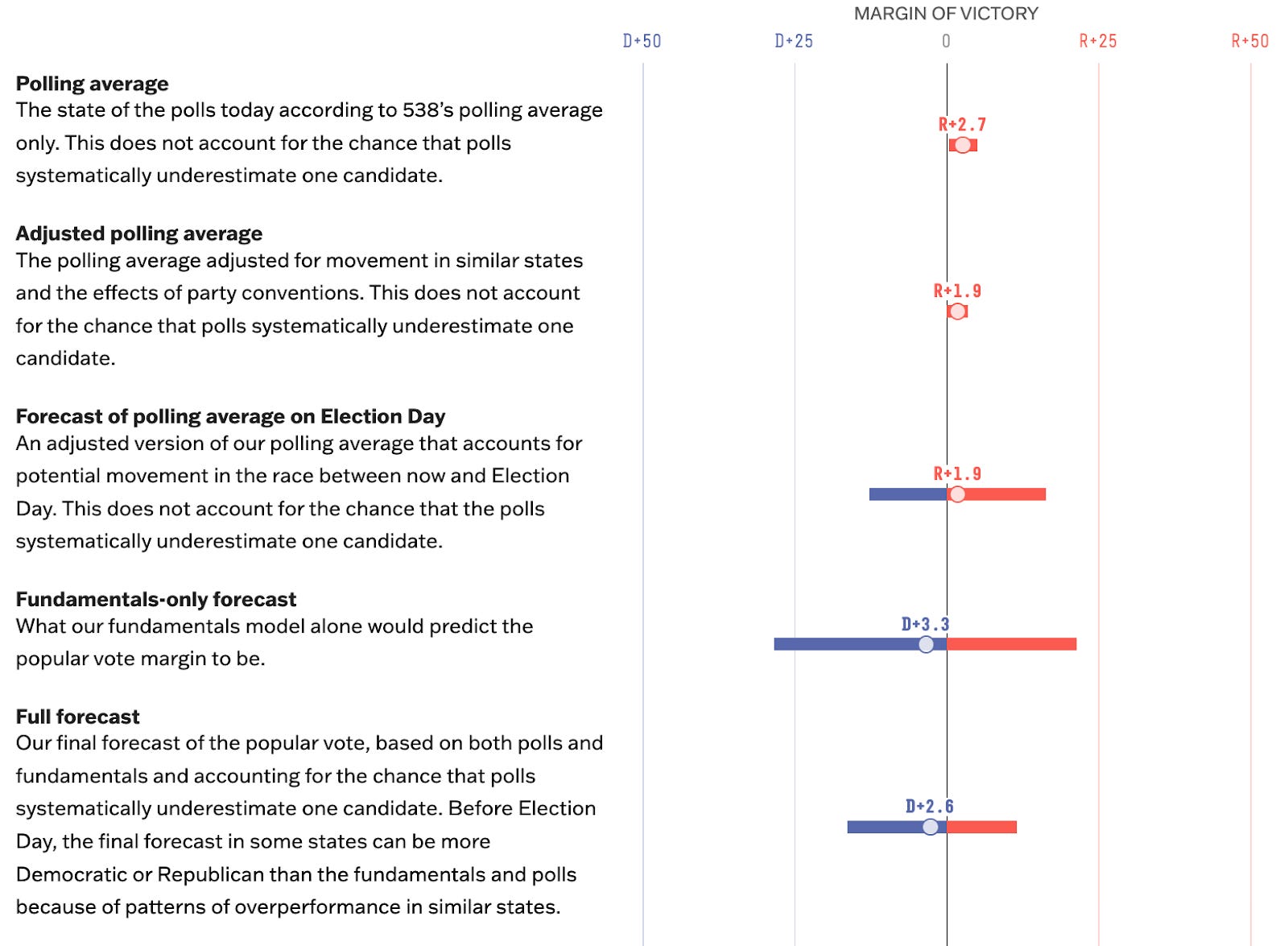
Here, their “full forecast” is Biden +2.6, which is somewhere in between polls (Trump +1.9) and fundamentals (Biden +3.3). So that’s internally consistent, at least. They’re obviously leaning more heavily into the fundamentals than the polls, though. Whereas our mix is roughly 70:30 in favor of polls, theirs is apparently about 15:85 in favor of fundamentals.
Now, that could at least theoretically be correct if they think the fundamentals are the more reliable indicator. The problem is, they don’t seem to think that, or at least not based on this chart they’ve published. Look at the error bar for their “fundamentals-only forecast”. It’s incredibly wide — notably larger than the error for their polling component.2 In fact, the 95th percentile probability distribution on their fundamentals estimate covers everything from roughly Trump +20 to Biden +30 (!), results that are nearly impossible in today’s highly polarized political environment.
So the chart is telling us that Morris doesn’t think the fundamentals are very informative at all. And yet, his model seemingly assigns 85 percent of the weight to the fundamentals. (I’m going to use terms like “seemingly” a lot because of the lack of transparency in what the 538 model is actually doing.) As a principle of model design, it’s almost axiomatic that if you’re blending two or more components into an average, you’ll want to place more weight on the more reliable component. But they’re doing just the opposite.
It also doesn’t explain what’s going on in Wisconsin or in other states like Ohio — where, to repeat, 538 has Biden doing much better in their full forecast than in either the polls or the fundamentals.
The explanation that Morris has given for this discrepancy is jargony and hard to parse. I might do a follow-up post where I try my best, but I’m reluctant to do his work for him. (He claims to be too busy to provide a longer explanation.) So far, what he’s written raises as many questions as it answers.
But what everyone should know is that statistical models like these are complex and can very easily go wrong. Models can contain coding errors — like, say, flipping a plus sign for a minus sign — or can suffer from incorrect data (e.g. mistakenly inputting an Alabama poll as an Arizona poll). But more than that, models have a lot of complicated components, and if you aren’t careful they can be less than the sum of their parts.
Moreover, it’s often hard to detect these design flaws through backtesting alone — usually you only learn the hard way once a model is stress-tested under real world conditions. (Because Morris’s model is new this year, it hasn’t endured one of those tests yet.) It’s a little bit like thinking you’ve engineered a good car, but for some reason the first time you test drive it, it continuously drifts to the left-hand side of the road and won’t go faster than 45 miles per hour. Sorry, but it’s time to go back to the lab when that sort of thing happens and not pass off a bug as a feature (“it’s actually good that you can only go 45 MPH because you’ll get in fewer accidents that way!”).
However, even if the 538 model is working as intended, I don’t think it’s informing us of much. Its thesis is basically this: Joe Biden is a reasonably clear favorite to win the popular vote because he’s an incumbent, and it’s too early to really update that assumption based on the polling or anything else. Indeed, you shouldn’t really think of the 538 model as a polling-based model at all, given that their forecast has actually moved in the opposite direction of the polling so far. I worry that people like Klain are interpreting the 538 model as saying Biden’s polling is fine, when it isn’t really saying anything about the polling.
Now, my understanding is that at some point, perhaps after Labor Day, the polling will begin to have more influence on the 538 model. I’ve frequently seen Morris cite this chart, for instance:

Basically, the chart says that polls don’t tell you very much until about 75 days before the election (roughly late August) at which point they begin to rapidly converge toward what they’re going to say on Election Day. This still isn’t a reason to favor fundamentals over polls, because the fundamentals are even less reliable according to 538’s calculations.3
But leave that aside for now. I also don’t really buy the chart and I think it badly exaggerates the amount of polling movement we’re likely to see. Why? Two reasons. One is that it’s based on state polls, not national polls. State polling averages are much noisier for various reasons, but mostly just because each state will only get polled a few times a month, or sometimes much less than that. Much of what a state polling average captures is just statistical noise, not real movement in the race. The error is going to be much less if you use the sort of fancy polling averages that 538 or Silver Bulletin do, which can combine state and national polls to give you a much more precise snapshot of the race. For instance, if there were two or three polls of West Virginia in the 1976 election between Jimmy Carter and Gerald Ford and they bounced around a lot, I don’t think that tells us very much about the current environment.
The other problem is that their estimates of polling movement are derived from polls since 1948 — but polls now are much less “swingy” than they once were. Let’s distinguish two concepts, as we do in the Silver Bulletin model. First, there’s how much the polls will move between now and Election Day. This is what we call “drift” in our forecast. And second, there’s uncertainty in how well Election Day polls will capture the actual result — what we call “error”.
Election Day “error” can still be fairly high — as it was in 2020 when polls considerably underestimated Donald Trump. However, in a time of extremely high polarization, “drift” is much less than it once was: the polls hone in toward their final margin earlier since few people’s votes are actually up for grabs. In some elections, like 2012 or this year, in fact, the polls barely move at all, even though things like felony convictions or debate disasters or assassination attempts:
As a result of these assumptions about polling movement, 538’s model is extremely uncertain about much of anything at this stage. For instance, they say that Biden has a 14 percent chance of winning the national popular vote by double digits. Our model says the chances of that are just 1.4 percent instead — note the decimal place. Or in Pennsylvania, 538’s 95th percentile forecast covers outcomes ranging from roughly Biden +18 to Trump +17. That’s almost certainly too wide of a range.
And it yields some weird artifacts: for instance, 538 has Texas as the 3rd-most likely tipping-point state, more likely to determine the election outcome than states like Michigan and Wisconsin. How come? Well, I presume it’s because Texas has a lot of electoral votes. And if you have as little faith as Morris does in the polling, a model is going to default to that, because we know exactly how many electoral votes Texas has (40) while the polling is more uncertain.

I also think their model gives Biden too much credit for being an incumbent in a polarized era where the incumbency advantage has considerably diminished. With that said, this isn’t that large a difference. My fundamentals model has Biden favored in the popular vote by roughly 2.5 points, whereas Morris’s has him ahead by 3.3.
The bigger difference is that Morris treats the fundamentals as a strong prior and I treat them as a weak one that you should be pretty eager to discard once you get enough polling. And I think one should be wary of strong priors in data-poor environments (only one election every four years) like election forecasting. Models based on fundamentals alone have a poor out-of-sample track record, not doing much better than a random guess. They also can’t account for factors like Biden’s age that are potentially highly material.4

As I wrote in the piece that introduced the Silver Bulletin forecast, there’s a fine line between an “objective” statistical model and “just some dude’s opinion”. All models inescapably include some degree of educated guesswork. But the 538 model falls somewhere on the wrong side of this line, in my view. It’s basically just Morris’s opinion that incumbency is still a powerful advantage, and you shouldn’t look at the polls until after Labor Day. He’s entitled to those opinions, although I think he’s wrong on each of those points. But intentionally or not, he’s designed his model in such a way as to be nearly impervious to contrary evidence.
Back when the brand name was stylized that way instead of as “538”.
Now, there may be some hidden steps they’re not showing explicitly. For instance, their chart only shows what they forecast the polling average to be on Nov. 5, not the actual result — the polls on Election Day could miss the mark.
If Morris doesn’t think either polls or fundamentals are reliable, perhaps that a reason not to publish a statistical forecast of the election until later in the race. It’s weird to publish a model that says “we basically don’t know anything so we’re defaulting to 50/50”. It’s fine to think that, but you don’t need a model for it.
For instance, if you had a sample of 1,000 presidential elections, maybe you’d find that candidates who are over 80 years old underperform the fundamentals by 3 points. With a smaller sample size, there really isn’t any good way to do that. (Although maybe you could use data from Congressional races.) But if you can’t, it’s at least a reason to trust the polls more than the fundamentals.
They should let Fivey decide who he wants to live with.
The biggest issue with the changes is that while the backend process for 538 has been totally overhauled, the front end report is very similar to how it always was. This can easily lead to people misinterpreting the report as comparable to the last few elections. Even if the new 538 models were sound, presenting the findings so consistently with such a different process wouldn't be much better.